CrowdStrike or: How I Learned to Stop Worrying and Love the Bomb


On the 18 July 2024 system administrators using Microsoft's Azure Central United States had a difficult day, a faulty update had blocked access to their storage and Microsoft 365 applications. Then on the 19 July at 4:09 UTC system a driver file update for Windows PCs caused system administrators and help desk staff across the globe to have an unbelievably dreadful day.
Truly dreadful.
Physical and virtual machines applying the update to CrowdStrike's Falcon software encountered a logic error, blue screened and then got stuck in a boot loop rendering the machine useless.
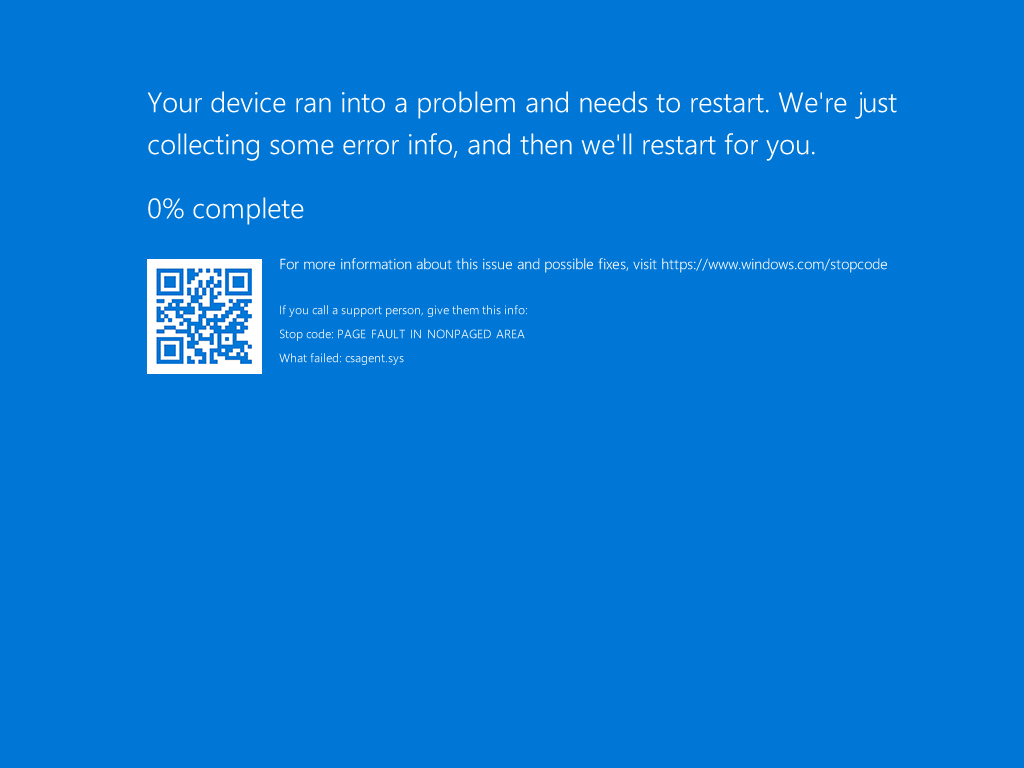
An hour later CrowdStrike reverted out the update stopping further machines from becoming crippled. The scale of the issue became apparent as around the world screens displayed the infamous blue screen of death in airports, banks, hotels, hospitals, tv studios, factories, government, and emergency service offices. What the IT industry had feared the Y2K bug theoretically would have done was now actually happening, the largest outage in the history of information technology.
And if things couldn't get any worse, they got worse. To fix the issue required booting the Windows machine into safe mode or the Windows Recovery Environment navigating to %WINDIR%\System32\drivers\CrowdStrike and then deleting any file matching C-00000291*.sys
As the machine wasn't getting to a stage where Group Policy could apply the fix it had to be done manually, and if the storage is encrypted by BitLocker, then you needed the recovery key as well (pity the poor Central United States sysadmins locked out of Azure).
The organisation that I work for doesn't use CrowdStrike, so our service desk didn't have to deal with repairing this issue. But these are my very rough calculations if we had.
530 Windows machines - desktop, laptops, servers (approximately)
10 minutes to:
- Boot into Windows Recovery Environment.
- Enter the BitLocker recovery key.
- Navigate the CrowdStrike directory.
- Delete the C-00000291*.sys files.
- Restart and test.
Note: speed of the machine's processor will affect how quickly you can get into the Windows Recovery Environment.
So, a total of 5300 minutes or 88 hours (approximately) and at 7.5 hours (average working day) almost 12 days for just one support desk operative (or admin) to manually go through and fix each machine. Sure, you can throw more bodies at the problem but that's all those bodies will be doing, nothing else.
And my calculations are working on the assumption that the machine is in the hands of the person who is going to fix it. Since COVID most staff now work remotely so organisations now have a huge logistical issue on their hands, do you retrieve the machine or attempt this fix remotely. Consider walking staff members through the necessary steps of deleting files in the System32 directory, you need to be precise on your instructions and that call isn't going to be ten minutes.
At the time of this article CrowdStrike is still at the top of the news agenda and likely to stay there over the next week. As more organisations recover their IT this incident will drop out of the news cycle and the temptation will be for life to continue as normal.
CrowdStrike is a trusted and well-respected security vendor, and its Falcon platform is supposed to protect organisations from threats. Life shouldn't be continuing normally; I'd hope that Chief Information Security Officers (CISO) and IT teams are now revising how they:
Trust but verify vendors' products and updates.
Either through complacency, time or cost implications patches are being applied straight to production. So, can your organisation afford sacrificial unicorns? And by sacrificial unicorns I mean machines which will have the updates applied before others and assigned to users who can provide useful descriptions of the issues instead of "its broken".
Disaster recovery.
When the IT hits the fan hard has your organisation the capability to retrieve, replace or remotely support all your users in getting them back up and running? Organisations should have run disaster recovery simulations before, I just hope that they considered the scale that currently needs to be dealt with.
The International Information System Security Certification Consortium, or ISC2 define security as the CIA triad of Confidentiality, Integrity, and Availability. On the 19 July 2024 data wasn't accessible when it was needed and organisations around the globe failed their users.